

La profilazione è una pratica trasversale a molteplici settori e attività del mercato: dalla personalizzazione di servizi digitali, all’ottimizzazione di processi aziendali, da applicazioni nel mondo del lavoro o perfino in sanità. Non vi è dubbio, poi, che in ambito marketing digitale la profilazione abbia trovato il suo terreno più fertile (e controverso). La possibilità di costruire profili dettagliati degli utenti, incrociare dati di navigazione, preferenze di acquisto e comportamenti cross-device, ha rivoluzionato le strategie commerciali. In tutti questi casi, un obiettivo comune è quello di comprendere, anticipare, talvolta orientare le decisioni dell’individuo attraverso l’elaborazione automatizzata delle sue caratteristiche personali, dei suoi gusti e delle sue abitudini.
Ma la capacità di “leggere” gli individui attraverso i dati comporta dei rischi significativi per i diritti e le libertà fondamentali, e la profilazione ha già da anni sollevato interrogativi giuridici ed etici che non possono essere ignorati. Il GDPR ci viene in aiuto con regole precise. Fin dal 2017 sono state oggetto di approfondimento nelle Linee guida WP251 del Gruppo di Lavoro Art. 29, che rappresentano ancora il quadro interpretativo più prezioso per comprendere quando e come la profilazione diventa lecita, quali basi giuridiche sono applicabili, e quali misure di trasparenza e sicurezza devono essere adottate.
Indice
Cosa si intende per profilazione nel contesto GDPR?
La profilazione, come definita dall’Art. 4 (4) del GDPR, è
qualsiasi forma di trattamento automatizzato di dati personali, finalizzata a valutare determinati aspetti personali relativi a una persona fisica, in particolare per analizzare o prevedere aspetti riguardanti il rendimento, le preferenze o il comportamento.
Potremmo parafrasarlo come l’utilizzo di algoritmi e sistemi informatici con lo scopo di trasformare dati grezzi in un “ritratto” dinamico del cliente, utile per personalizzare servizi e comunicazioni. In particolare, la definizione evidenzia tre elementi, tutti essenziali:
- Per essere profilazione, il processo dev’essere automatizzato. Attenzione, però: integrare fasi manuali non deve portare a escludere la possibilità di profilazione. La presenza di un intervento umano in qualche fase operativa implica che il processo non è più interamente o unicamente automatizzato. Questo può certamente contribuire a limitare i rischi (pensiamo ad esempio all’importanza della supervisione umana nei sistemi AI). Tuttavia, per soddisfare questo criterio della profilazione, è sufficiente il ricorso a strumenti tecnologici e database in una qualsiasi fase dell’attività.
- Per essere profilazione, l’attività deve riguardare dati riferiti a persone fisiche. Insomma, il perimetro di applicazione è quello stabilito dal GDPR e alla sua definizione di dato personale. Questa precisazione sembra banale ma è rilevante. Si pensi ai dati di navigazione sul web, spesso considerati meri dati tecnici in USA. L’approccio europeo invece li tutela al pari di altre informazioni personali, nella misura in cui il loro trattamento può avere un impatto sulla vita delle persone. Impatto che va dalla possibilità di mostrare annunci pubblicitari mirati, a un rischio più generalizzato, legato alle potenziali attività di controllo derivanti dalla creazione di profili basati sull’analisi di indirizzi IP, cookie, tag, ecc.
- Per essere profilazione, dev’esserci una valutazione o un giudizio sulla persona. Il processo di profilazione implica la capacità di analizzare e interpretare i dati in modo da valutare aspetti specifici dell’individuo, come le sue preferenze, comportamenti o performance. Queste conclusioni, spesso, sono utilizzate per formulare previsioni sulla persona, con l’effetto di poterne influenzare i comportamenti o le decisioni. Il caso tipico è quello della piattaforma di streaming: dopo ore trascorse ad ascoltare Miles Davis, vengo registrato come “amante del jazz”, e ottengo un accesso più rapido alla musica di questo genere.
Quando è “profilazione” e quando no?
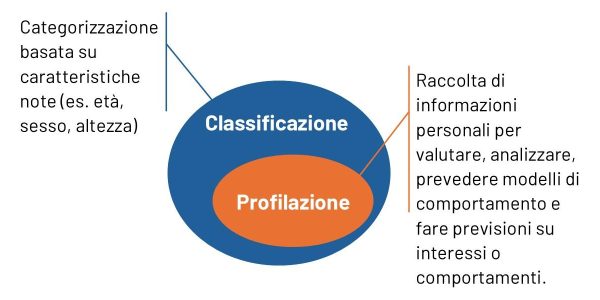 In termini astratti, e nei casi palesi, la profilazione è abbastanza chiara. Ma in molte circostanze più “borderline”, non è sempre facile stabilire se il trattamento di una determinata informazione sia da considerarsi come una valutazione o un giudizio sulla persona. Partiamo innanzitutto da una necessaria distinzione, quella tra profilazione e “classificazione”.
In termini astratti, e nei casi palesi, la profilazione è abbastanza chiara. Ma in molte circostanze più “borderline”, non è sempre facile stabilire se il trattamento di una determinata informazione sia da considerarsi come una valutazione o un giudizio sulla persona. Partiamo innanzitutto da una necessaria distinzione, quella tra profilazione e “classificazione”.
Mentre la classificazione si limita a raggruppare i dati in categorie predefinite per fini statistici o organizzativi, la profilazione va oltre, utilizzando l’analisi dei dati per prevedere comportamenti e personalizzare l’esperienza dell’utente. Applicata a un e-commerce, questa differenza potrebbe manifestarsi nei seguenti casi:
• Classificazione: l’e-commerce suddivide i clienti in base alla fascia d’età per redigere report statistici. L’obiettivo è quello di ottenere una panoramica aggregata, senza trarre conclusioni sul singolo individuo.
• Profilazione: lo stesso e-commerce analizza in profondità il comportamento di navigazione e gli acquisti effettuati per inviare offerte personalizzate e suggerire prodotti che potrebbero essere di interesse specifico per ciascun cliente. Qui l’obiettivo è predittivo e personalizzante, con un impatto diretto sull’utente.
Le tre fasi della profilazione
Possiamo riconoscere facilmente un’attività di profilazione osservando il modo in cui si sviluppa, con un processo che tipicamente attraversa tre macro-fasi principali.
La prima è la raccolta dei dati, vale a dire la creazione e l’aggiornamento di database, anagrafiche o liste di contatti, arricchiti progressivamente con tutte le informazioni utili sull’utente o sul cliente.
Segue poi la fase di analisi automatizzata, in cui i dati vengono elaborati per individuare correlazioni, schemi o tendenze. È qui che compaiono le prime valutazioni, sotto forma di etichette, “tag” o dati aggiuntivi. Gli individui vengono così ricondotti a specifiche categorie (es. “cliente reattivo alle promozioni”, “appassionato di cinema d’azione”, “collezionista di prodotti di una certa marca”, ecc.).
Infine, arriva la fase di applicazione delle correlazioni. I profili creati vengono utilizzati per prendere decisioni o orientare strategie. Può trattarsi, ad esempio, di iniziative di up-selling e cross-selling basate sugli acquisti precedenti, dell’invio di newsletter con contenuti personalizzati, o di campagne di retargeting costruite a partire da “custom audience” generate automaticamente.
[ved. anche GDPR nel retargeting, prospecting e Custom Audience]
Un’ulteriore domanda da porsi, quando si organizzano i dati, potrebbe essere: “Sto semplicemente catalogando, o sto preparando uno strumento che influenzerà il modo in cui saranno trattate le persone?”. Proviamo allora a mettere in pratica la riflessione con qualche scenario ipotetico.
SEGMENTAZIONE DELLA NEWSLETTER
Un’azienda raccoglie alcuni dati di base dichiarati dagli utenti, come l’età o il genere, e li utilizza per inviare messaggi differenziati ai vari gruppi, ma non va oltre una semplice suddivisione della platea in blocchi statici. Qui non c’è un vero e proprio giudizio sulla persona né un’analisi volta a prevederne comportamenti o preferenze future: si tratta quindi più di una classificazione che di una profilazione in senso stretto.
CONTENUTI DINAMICI SUL SITO WEB
Abbiamo un’azienda che osserva il comportamento degli utenti, ne registra le interazioni e lascia che il sistema aggiorni in modo continuo gli indicatori probabilistici utilizzati per mostrare elementi personalizzati nel sito (es. acquisti suggeriti). In questo caso, non ci si limita a collocare l’utente in una categoria, ma si analizzano i dati per anticiparne le mosse e personalizzare in tempo reale ciò che vede. La valutazione e la previsione, elementi chiave della profilazione, sono al centro del processo.
TARGETING PER CLUSTER SPECIFICI
Questa volta, l’azienda combina informazioni dichiarate, come la professione, con dati comportamentali raccolti online, per stabilire a quali gruppi omogenei appartengono gli utenti. L’assegnazione a un “cluster” non è una mera etichetta: è il risultato di un’interpretazione che attribuisce un significato ai comportamenti e li traduce in una decisione operativa, ossia la selezione dei destinatari per l’invio di specifiche promozioni. Senza dubbio abbiamo a che fare con profilazione.
Obblighi e divieti nella profilazione
Quando un’azienda svolge o intende svolgere attività di profilazione, deve essere consapevole che il GDPR impone precisi obblighi e pone chiari divieti. La conformità non è solo un requisito legale, ma anche un presupposto di fiducia verso clienti e utenti. Ecco allora i principali ambiti da presidiare.
Liceità della profilazione: consenso o legittimo interesse?
La scelta della base giuridica rappresenta un passaggio fondamentale. Nel campo della profilazione, il GDPR offre diverse possibilità, ma le due basi principali sono il consenso e il legittimo interesse.
Il consenso è senza dubbio necessario in tutte le situazioni in cui la profilazione sia invasiva, non attesa o riguardi dati particolari. Come sempre, il consenso alla profilazione dovrà essere libero, specifico e granulare. Quando la profilazione supporta attività di marketing, ad esempio, non basterà un “sì generico”, e l’iscrizione a una DEM dovrà essere tenuta ben distinta dalle attività di profilazione che, con un consenso dedicato, potranno arricchire il livello di personalizzazione delle DEM stesse.
Il legittimo interesse del titolare potrà invece giustificare, in alcune circostanze, forme di profilazione più leggere. Tuttavia, mantenere un adeguato livello di accountability potrebbe non essere un lavoro semplice. Nell’ambito della profilazione, per effettuare e superare un adeguato “balancing test”, con cui ponderare l’interesse dell’azienda con i diritti degli interessati, sarà opportuno valutare diversi fattori:
- quanto è dettagliato il profilo (un’etichetta generica o una segmentazione molto granulare),
- quanto è completo il profilo (descrive solo un aspetto marginale o un quadro complessivo della persona),
- quali effetti produce concretamente sull’individuo,
- quali garanzie vengono adottate per assicurare correttezza, accuratezza e non discriminazione.
Le Linee guida WP251 suggeriscono in ogni caso una certa cautela. Si evidenzia, ad esempio, che sarebbe difficile per un titolare giustificare il ricorso al legittimo interesse come base legittima per pratiche intrusive di profilazione e tracciamento per finalità di marketing o pubblicità, ad esempio quelle che comportano il tracciamento di persone fisiche su più siti web, ubicazioni, dispositivi, servizi o l’intermediazione di dati. Se si considera poi che il diritto di opposizione per la profilazione ai fini di marketing, gode di un’applicazione privilegiata, assoluta e immediata, è utile partire dal presupposto che il consenso dovrà essere la base giuridica di elezione – sebbene, in termini di principio, non esclusiva.
Trasparenza nella profilazione
Come per ogni forma di trattamento di dati personali, le persone hanno diritto a capire come funzionano le operazioni applicate alle informazioni che le riguardano. Se parliamo di trasparenza nella profilazione, l’impegno dovrà essere quello di riuscire a spiegare, in modo chiaro e comprensibile per il nostro target, se e come questa venga svolta, attraverso quali dati e con quali logiche.
Non si tratta quindi di limitarsi a dichiarare di “fare profilazione”. L’informazione di valore è quella in cui si chiarisce quali logiche sono state impiegate per assegnare un utente a una categoria, e quali effetti concreti possono produrre tali valutazioni. Immaginiamo un istituto di credito che utilizza sistemi di profilazione per valutare l’affidabilità dei clienti. Senza entrare in tecnicismi sugli strumenti statistici utilizzati, nella propria informativa privacy potrebbe spiegare che il sistema analizza alcuni fattori come la puntualità nei pagamenti, il rapporto tra entrate e spese e la frequenza di utilizzo dei servizi finanziari, per assegnare l’utente a una categoria di rischio (basso, medio, alto), la quale a sua volta potrà incidere sull’approvazione di un prestito o sulle condizioni economiche applicate.
Si consideri, peraltro, che una peculiarità della trasparenza nella profilazione riguarda il fatto che all’utente va garantito il diritto non solo a poter accedere ai dati di input (su cui sono state basate le successive valutazioni), ma anche le informazioni di output, ossia i profili generati, e i segmenti di appartenenza a cui è stato assegnato (e non reggerà il tentativo di aggirare la regola o negare l’accesso e le spiegazioni facendo leva sulla tutela di segreti industriali).
Qualità e contestabilità della profilazione
Un profilo, per essere legittimo, deve poggiare su basi solide. Quest’affermazione chiama in causa il principio di esattezza nel trattamento di dati personali. In termini pratici, significa che gli algoritmi e le procedure adottate per effettuare la profilazione devono funzionare correttamente, le “etichette” attribuite a un utente devono essere veritiere e aggiornate, e il rischio di errori va minimizzato.
Poiché la profilazione comporta frequentemente elementi predittivi, il margine di inesattezza potrà tuttavia inevitabilmente essere elevato. Si pensi all’assegnazione di una persona in una categoria da cui questa non si senta rappresentata. Un esempio classico, spesso citato con ironia, è quello del consumatore che acquista una lavatrice e, subito dopo, viene tempestato di pubblicità di altre lavatrici. È evidente che chi ha appena comprato un elettrodomestico simile non avrà alcun interesse a comprarne un altro a breve. Un caso che mostra come un’etichetta attribuita sulla base di un dato reale possa però risultare imprecisa o mal calibrata, generando più frustrazione che valore.
Un altro rischio, forse meno palese ma decisamente più serio (e discusso) riguarda la c.d. filter bubble. Un effetto che nei processi di profilazione tende a rinchiudere l’utente in una bolla di contenuti personalizzati, basati sulle sue scelte passate, senza lasciare spazio alla scoperta o al confronto con prodotti, idee, opinioni, nuovi o differenti. Se da un lato la profilazione può aumentare la pertinenza delle proposte, dall’altro può impoverire l’esperienza di navigazione e non corrispondere ai desideri reali dell’utente, che magari vorrebbe esplorare novità e alternative non previste dal profilo assegnato.
Anche per questi motivi, gli interessati hanno diritto a rettificare i dati, contestare i profili attribuiti e aggiungere dichiarazioni integrative. Non solo i dati di input, ma anche i profili di output rientrano, normalmente, in questo diritto di correzione.
Categorie di interessati da tutelare e profilazione con dati particolari
Il GDPR pone un’attenzione speciale verso i soggetti più vulnerabili e verso le categorie di dati più sensibili.
Il Considerando 71 del GDPR, ad esempio, evidenzia che i minorenni non dovrebbero mai essere soggetti a trattamenti finalizzati alla profilazione. Dopotutto, il rischio di trasformare una “previsione” in una forma di “condizionamento” è più elevato nei minori, caratterizzati da una personalità in crescita e in evoluzione. In queste circostanze, assegnare un profilo può avere conseguenze sproporzionate sulla formazione, sulle scelte, sui gusti, e complessivamente sullo sviluppo dell’identità. Tantopiù se rientriamo nel perimetro della forma più frequente di profilazione, cioè quella svolta a fini pubblicitari su piattaforme online, dove contenuti e annunci personalizzati potrebbero influenzare comportamenti o decisioni, con impatti più marcati sui minori rispetto agli adulti.
Quanto ai dati particolari – salute, opinioni politiche, convinzioni religiose o filosofiche, orientamento sessuale – il livello di cautela deve essere massimo. Le WP251 ricordano che, pur non essendo vietata in assoluto, la profilazione basata su questi dati espone a rischi particolarmente elevati di discriminazione, in forme non così diverse da quanto può avvenire coi bias dell’Intelligenza Artificiale, che rischiano di amplificare stereotipi esistenti e forme di pregiudizio. Così come un algoritmo può decidere tariffe assicurative più alte per gruppi specifici sulla base di dati storici, allo stesso modo la profilazione basata su dati particolari rischia di tradurre in decisioni concrete disuguaglianze già presenti nella società.
È importante sottolineare che le situazioni in cui una profilazione basata su dati particolari possa ritenersi effettivamente necessaria sono molto rare. In genere, l’uso di dati così delicati per finalità di profilazione comporta un rapporto rischi/benefici sfavorevole, richiedendo l’adozione di misure rafforzate di tutela: pseudonimizzazione o anonimizzazione dei dati, accessi limitati a personale qualificato, valutazioni d’impatto sulla protezione dei dati (DPIA) approfondite, trasparenza rafforzata verso gli interessati e, senza dubbio, consenso esplicito e specifico. Attenzione, poi, anche ai casi in cui il dato particolare non è quello direttamente raccolto, e su cui si basa la valutazione, bensì quello inferito dal sistema: ad esempio, l’analisi automatizzata di una serie di acquisti o ricerche online potrebbe portare a dedurre l’esistenza di una condizione di salute, generando profili altrettanto sensibili pur senza che l’interessato abbia mai inteso comunicare quell’informazione – o addirittura non ne fosse a conoscenza.
[Ved. anche Dati sensibili: quali sono e come trattarli secondo il GDPR]
Gestione dei rischi e conservazione dei dati di profilazione
Ogni volta che un titolare intende avviare attività di profilazione su larga scala o sistematica, la valutazione d’impatto sulla protezione dei dati (DPIA) diventa obbligatoria. Non si tratta di un mero adempimento formale, ma di uno strumento essenziale per identificare e gestire i rischi: attraverso la DPIA, l’azienda mappa i flussi di dati, individua i rischi per gli interessati e definisce le misure di mitigazione più appropriate. Nell’ambito della profilazione, coinvolgere rappresentanti dei propri utenti o clienti nel processo, potrebbe essere particolarmente utile per calibrare le aspettative, migliorare la trasparenza e prevenire eventuali contestazioni.
Analogamente, è fondamentale che la conformità al GDPR sia incorporata fin dalla progettazione di un’attività così delicata come la profilazione. Nel rispetto dei principi di privacy by design e privacy by default, flussi e sistemi andranno costruiti in modo da ridurre al minimo la quantità di dati utilizzati per creare i profili, da adottare logiche di aggregazione o segmentazione piuttosto che profilazioni non strettamente necessarie, e configurare i parametri affinché i profili siano il meno invasivi possibile rispetto alla sfera personale dell’interessato. Privacy by default, in questo contesto, potrebbe implicare anche che all’utente sia lasciata la possibilità di attivare volontariamente vari livelli di profondità dell’analisi, e solo se e quando realmente desiderato. Inoltre, deve essere sempre semplice per gli interessati comprendere quali fattori incidono sulla creazione del profilo e avere chiare le proprie possibilità di modificare o limitare le proprie preferenze.
In stretta connessione con questi principi, un aspetto cruciale è la limitazione della conservazione dei dati. I profili non possono essere mantenuti illimitatamente, ma devono essere cancellati o anonimizzati una volta esaurita la finalità. Il Garante, ad esempio, ha chiarito che una conservazione decennale dei dati raccolti tramite fidelity card è sproporzionata, indicando come congruo un termine di circa 12 mesi per le attività di profilazione connesse. La determinazione dei tempi di conservazione (e dei tempi di validità del consenso) dovrà quindi avvenire nel solco della DPIA e della privacy by design, con una valutazione preventiva sulla reale necessità e proporzionalità del periodo scelto, così da garantire coerenza tra minimizzazione, finalità dichiarate e tutela effettiva degli interessati.
[Ved. anche Fidelity card: un trattamento dati ancora spinoso ]